На даний момент я більше виступаю як поціновувач візуальної даних, ніж створювач як такої. Тож значимість підготовки візуалізації до сприйняття її читачами — стає актуальнішою :) На тему сприйняття візуальної інформації на сьогоднішній день зроблено багато досліджень, виступів, написано статтей. Деякі з них ви вже могли читати власноруч, про деякі чути. Але як показує досвід: в Україні до них не завжди прислухаються. Як приклад, альбом WTF viz Ukraine блогу Textura.in.ua. Тому вважаю за потрібно написати на цю тему.
Чому це важливо? Це як з правилами протипожежної безпеки — вони наче прості та логічні, але невиконання часом може призвести до негативних наслідків. Вчимося на досвіді інших.
За основу взята стаття Kennedy Elliott, журналістки The Washington Post, під назвою «39 studies about human perception in 30 minutes«, яку вона написала на Medium після виступу на Конференції OpenVis 2016. Далі йтиме моя вільна вижимка-переклад.
Перші дослідження
Одною з базових наукових робіт, на яку зсилаються, на мою думку, більшість книжок з візуалізації даних, вважається «Graphical Perception: Theory, Experimentation, and the Application to the Development of Graphical Methods.» William Cleveland, Robert McGill, 1984. Вона доступна free за лінком.
Це дослідження дає нам рейтинг так званих «елементарних завдань сприйняття» (за швидкістю сприйняття — прим. перекладача), які є самими основними візуальними завданнями, що ми виконуємо при сприйнятті графіків. У верхній частині рейтингу знаходиться найпростіша задача сприйняття — «позиція по загальній шкалі». Ми дешифруємо її першою. Для всіх інших потрібно більше часу та зусиль на дешифрацію. Cleveland і McGill кажуть, що це найпростіше для нас — порівняти об’єкти з точки зору загальної шкали, наприклад, позицію точок по одній осі координат. Діаграми розсіювання є хорошим прикладом цього: кола в діаграмах розсіювання закріплені на двох загальних масштабах, осі X та осі Y.
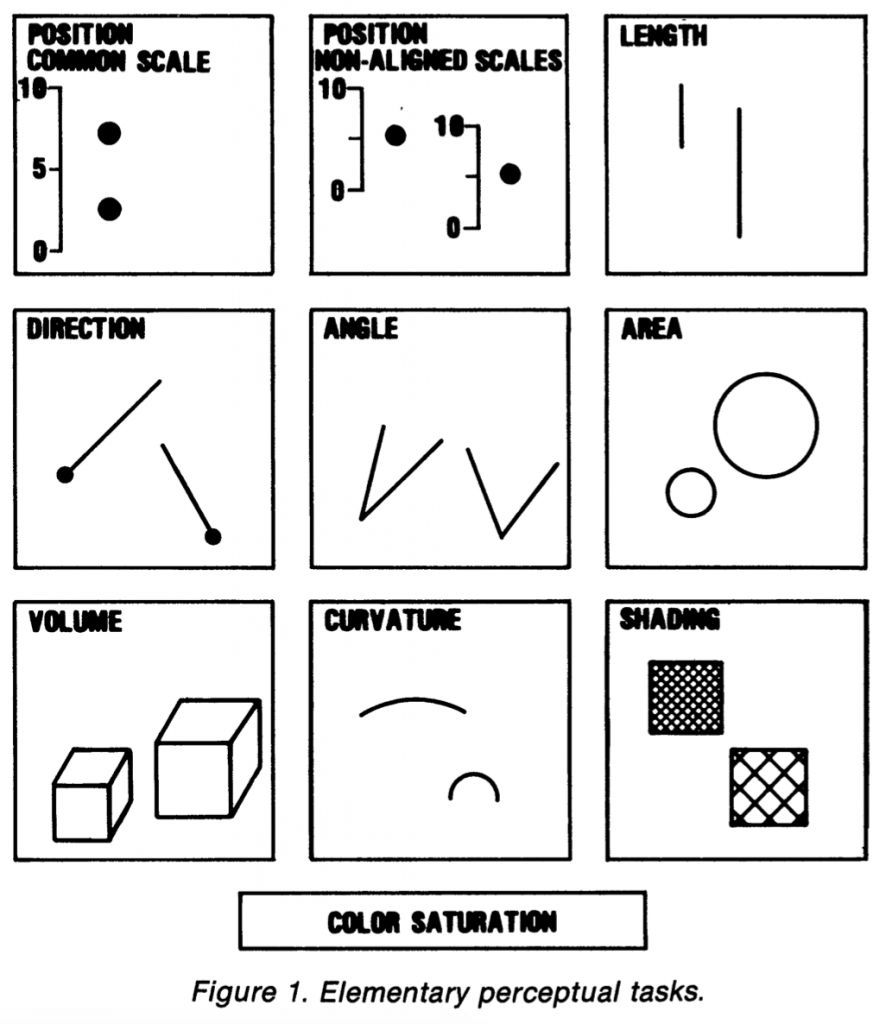
Perceptual tasks — Cleveland and McGill
Актуальність цих досліджень, яким вже більше 30 років, перевіряли в статті «Crowdsourcing Graphical Perception: Using Mechanical Turk to Assess Visualization Design.» Jeffrey Heer and Michael Bostock, 2010 (доступна за лінком). Результати нового дослідження були схожі на попередні результати.
Вплив візуальних опорних точок
За законом Стівена (на жаль, посилання не знайшов на оригінал): коли об’єкт розглядається в контексті інших великих об’єктів, він сам здається більшим, коли розглядається в контексті з більш дрібними об’єктами, сприймається меншим. Jordan і Schiano (лінк на статтю) виявили, що збільшення простору між лініями справило протилежний ефект. Якщо лінії були досить близько одна до одної, довжина лінії була більш схожою на довжину лінії біля неї (цей ефект також називаються — асиміляцією). Якщо лінії були далеко один від одної, довша лінія здавалася довшою, а коротка лінія — коротшою (цей ефект також називаються — контрастом).
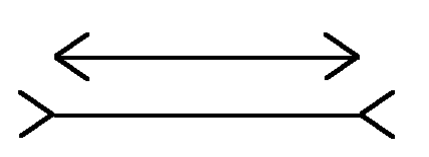
Ще один приклад візульного впливу зовнішніх елементів на довжину однакових ліній
Базові фігури
Croxton в своїй статті від 1932 року (лінк) виявив, що стовпчики були більш ефективні для порівняння значень, ніж кола, квадрати або кубики. Кола і квадрати були ефективніші за інших — та зайняли друге місце. Кубики були, безсумнівно, найгіршими. Питання про 3D розглянуте пізніше.
Але як ви можете здогадатися, тут дуже файно лагають результати досліджень з першого блоку, Cleveland і McGill. — коментар перекладача
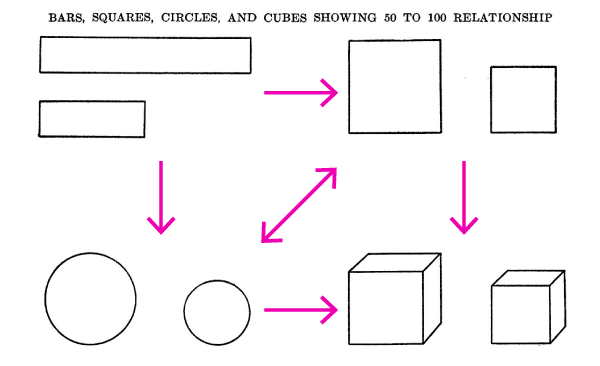
Croxton виявили, що учасники були більш точними, коли вони порівняли розміри прямокутників різної довжини. Між точністю, коли використовувалися квадрати чи кола, не було сильної різниці. Всі три попередні фігури давали кращі результати, ніж куби.
Постійна боротьба: Стовпчики та кола для відображення пропорцій
Дискусія, щодо використання для відображення пропорції кругову чи стовпчикову діаграму, виникає постійно. Часом можна почути, що не варто використовувати кола для відображення пропорцій, проте Kennedy Elliott не знайшла жодної статті, де б заборонялося використовувати кругові діаграми.
Eells був одним з перших, хто вивчав цю тему. Він опублікувати статтю в 1926 році(лінк). В його час, кругові діаграми були осміяні за те, що порушували адекватність сприйняття. Наприклад, тоді вважалося, що людське око не може дуже ефективно оцінювати дуги, кути або хорди.
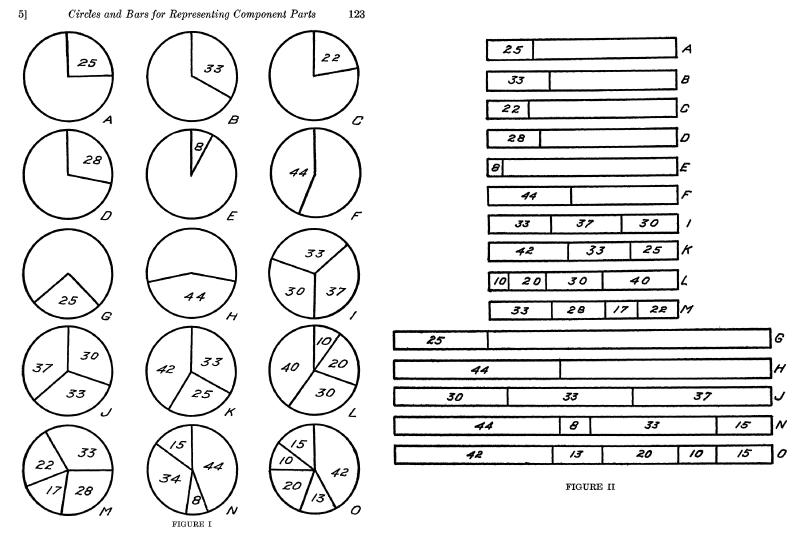
Eells видавав в класах психології два листи: наборами кругових та стопчикових діаграм — і попросив учасників оцінити частку кожного сегмента в цілому.
Дослідник хотів знати як відбувається процес аналізу кіл. То ж Eells роздавав свої тести в класах психології та просив оцінити пропорції в кругових та стовчикових діаграмах.
Мало того, що він дізнався, що кругові діаграми читалися легше, швидше та точніше, за гістограми, але як тільки кількість компонентів в графіку збільшувалася, стовпчики ставали менш ефективними при кодуванні даних. Зворотне вірно для кругових діаграм.
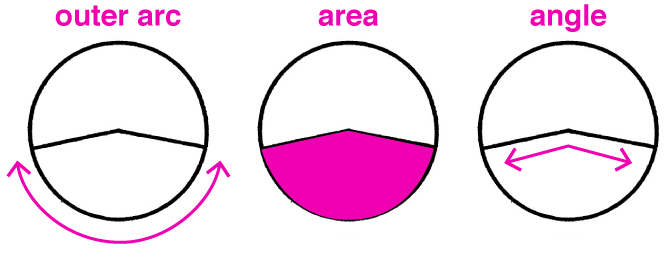
Три способи, якими учасники дослідження Eells визначали пропорцію в кругових діаграмах. Тільки одна жінка використовувала хорду для, мабуть, через те, що вона мала деякі знання до цього. Вона найточніше визначала пропорції в класі.
Він виявив, що 50 відсотків людей використовують зовнішню дугу, щоб зробити судження щодо пропорцій, в той час як 25 відсотків використовують площу, а інші 25 відсотків використовують внутрішню дугу або кут. Крім того, 71 чоловік в класі віддали перевагу круговим діаграмам, і тільки 25 — стовпчиковим. Він прийшов до висновку, що ми повинні використовувати кругові діаграми, не тільки за їх привабливость, але через їх наукову точність.
Simkin та Hasti (лінк на статтю) просили учасників робити пропорційні судження та порівняння між сегментами («segment-to-segment (comparison) judgments»). І виявили, що порівняння сегментів, прості стовпчикові діаграми працюють краще, за ними йдуть розділені стовпчикові діаграми(» «), а вже за ними кругові діаграми. Simkin та Hasti прийшли до висновку, що люди мають певну схему для того, що очікувати при перегляді конкретної діаграми. Для пропорційних суджень, кругові діаграми та розділені стовпчики були схожі за ефективністю, в той час прості стовпчикові діаграми були найменш ефективними.
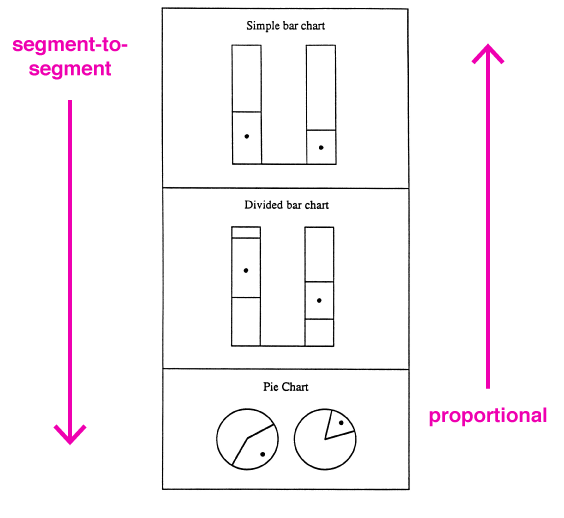
Simkin та Hastie зробили висновок, що кожен має певну схему того, що очікувати, коли ти бачиш ту чи іншу діаграму.
Spence та Lewandowsky (лінк) виявили, що порівняння між декількома сегментами займає більше часу і мають більш низьку точність. Найгірше застосовувати кругові діаграми, коли потрібно порівнювати кілька сегментів. Також автори виявили, що таблиці ліпше не використовувати, окрім варіанту з абсолютними значеннями, незважаючи на те, що радить Тафт.
Hollands та Spence (лінк) виявили, що при зростанні кількість компонентів в стовпчикових діаграмах, їх ефективність при передачі порівняння пропорцій зменшується. Насправді, для кожного нового компонента в стовпчиковій діаграмі, читачу потрібно додаткові 1,7 секунди для обробки.
Стовпчики та лінії
У двох окремих експериментах в одному з досліджень, Zacks та Tversky (лінк) виявили, що коли учасникам були показані стовпчикові діаграми та попросили описати дані, вони постійно акцентували увагу на різниці між змінними(наприклад, «А на Х більше, ніж Б » — дискретна величина). У той час як з лінійними графіками, учасники описували тренди/тенденції (наприклад, «при збільшенні Х, Y теж росте»).
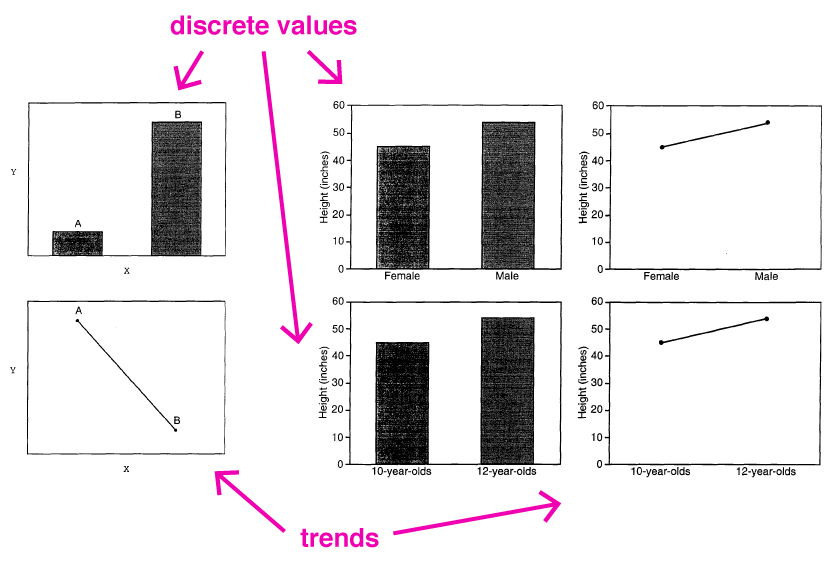
Zacks та Tversky дійшли висновку, що учасники найчастіше описували різницю між значеннями на осі Х, коли їм показували стовпчикові діаграми, та взаємозв’язок, коли їм показували лінійні графіки.
Навіть коли дослідники в іншому досліджені (лінк) представили учасникам графік, в який додали третю змінну, опис в лінійних діаграмах зосередився на х-у співвідношені, в той час як в стовпчикових — учасники намагалися включити цю нову змінну.
Ці дослідження показують, що люди мають складність у виявленні повідомлень, що не відображають трендів/тенденцій, в лінійних графіках.
Стопчики, кола та лінії
Hollands та Spence (лінк) оцінювали, чи залежить ефективність діаграми від типу судження, яке має бути зроблено. Вони вважали, що лінійні графіки будуть кращі за інші графіки, що показують зміни, тому що вони мають «інтегроване» відображення (“integrated” interfaces): глядачі здатні сприймати зміни безпосередньо по схилу лінії. Використання кругових діаграм для зображення зміна вимагає кількох послідовних діаграм, використовуються «окремі» інтерфейси (“separated” interfaces), а, отже, поступаються.
В своєму першому експерименті Hollands and Spence пропонували учасникам ці три графіки для того, щоб зрозуміти наскільки точно вони оцінюють зміни.
Вони перевірили сприйняття учасників змін та пропорції між стовпчиковими, круговими та лінійними діаграмами.
Кругові діаграми явно програвали при відображенні інформації про зміну. Проте автори виявили, що стовпчикові діаграми мали такий же успіх з лінійними графіками, і вони задалися питанням, чому.
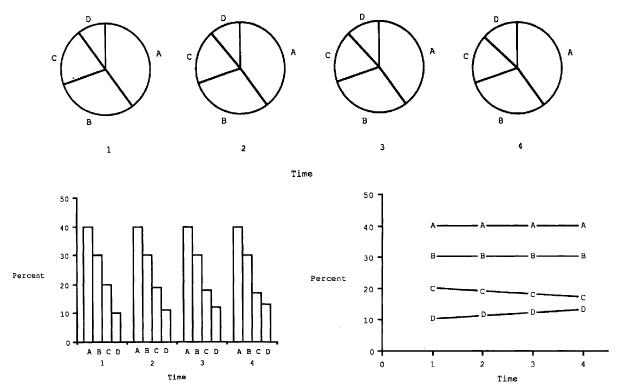
Вони припустили, що це відбувалося, тому що люди малювали уявні лінії між сповпчиками. Таким чином, вони створили новий, «страшний» графік, що називається багаторівневою діаграмою (див. Мал 1), що б розбити ці уявні лінії, і знову протестували учасників.
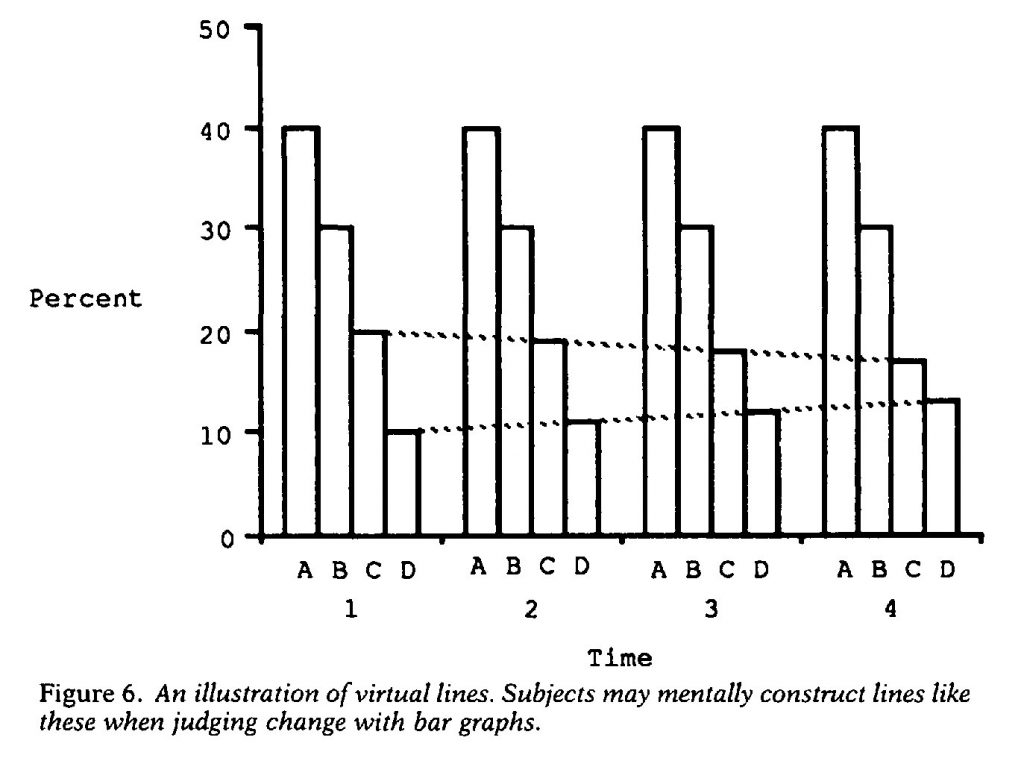
Hollands and Spence припустили, що причиною того, що стопчикові діаграми так само добре передають зміни, як і лінійні графіки, було те, що учасники малювали уявну лінію між стовпчиками, щоб відслідкувати зміни.
Їх теорія підтвердилася, справді, будь-яка діаграма, що дозволяє читачеві побачити реальну або уявну лінію тренда, була кращою в передачі змін. Для відображення пропорцій, якщо графіки немає одиниць виміру, кругові діаграми були кращими.
Лінійні графіки
Лінійна форма може бути повна контекстом, що не тільки привертає нашу увагу, а й спотворює наше сприйняття даних.
Як відомо, незалежна змінна (причина), як правило, розміщується на осі X, а залежна змінна (ефект) на осі Y. Але ми також схильні сприймати нахил як показник швидкості змін, висоти або суми. Ці два підходи можуть викликати конфлікт у сприйнятті.
Gattis та Holyoak (лінк) розробили експеримент, де нахил може вказувати висоту зміни, або висоту над рівнем моря, але це означає, що незалежні і залежні змінні були розміщенні на неправильних осях. Автори представили як правильний так і неправильний графік учасникам і запитали, на що вказує пунктирна лінія: на швидку чи повільну змінну.
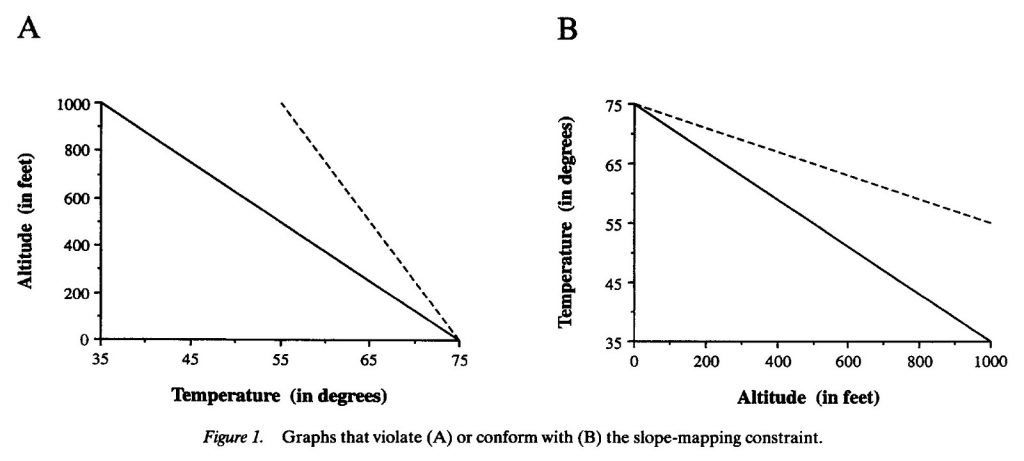
Згідно загальної практики, висота над рівнем моря має вказуватися на осі Х, як незалежна змінна. Проте, зображення її на осі Y, дозволяє сприймати нахил кривої як ілюзію висоти.
Коли висота була на осі Y, що відповідає візуальній метафорі, учасники були більш точними. Іншими словами, ми схильні бачити нахил в якості представника швидкості, висота, кількість або швидкість зміни всього вище названого. Автори дійшли до висновку, що існують певні образотворчі властивості нахилу, які «полегшують міркування вище всіх інших.»
Вони також виявили універсальну асоціацію «більше» або «краще» з рухом вгору.
Carswell та інші (лінк) виявили, що, коли лінійні графіки показали зворотній тренд, люди вивчали їх більше. Вони виявили, що це не той випадок, коли воно залезжить від кількість точок даних, симетрії або лінійності.
3d графіки
Далі чотири дослідження, які показують, що ми оцінюємо 3D-об’єкти більш точно, ніж ми зазвичай думаємо. Два з цих досліджень окремо відкидають популярну філософію «високий коефіцієнт даних до фарби» («high data-to-ink ratio»), описану Tufte.
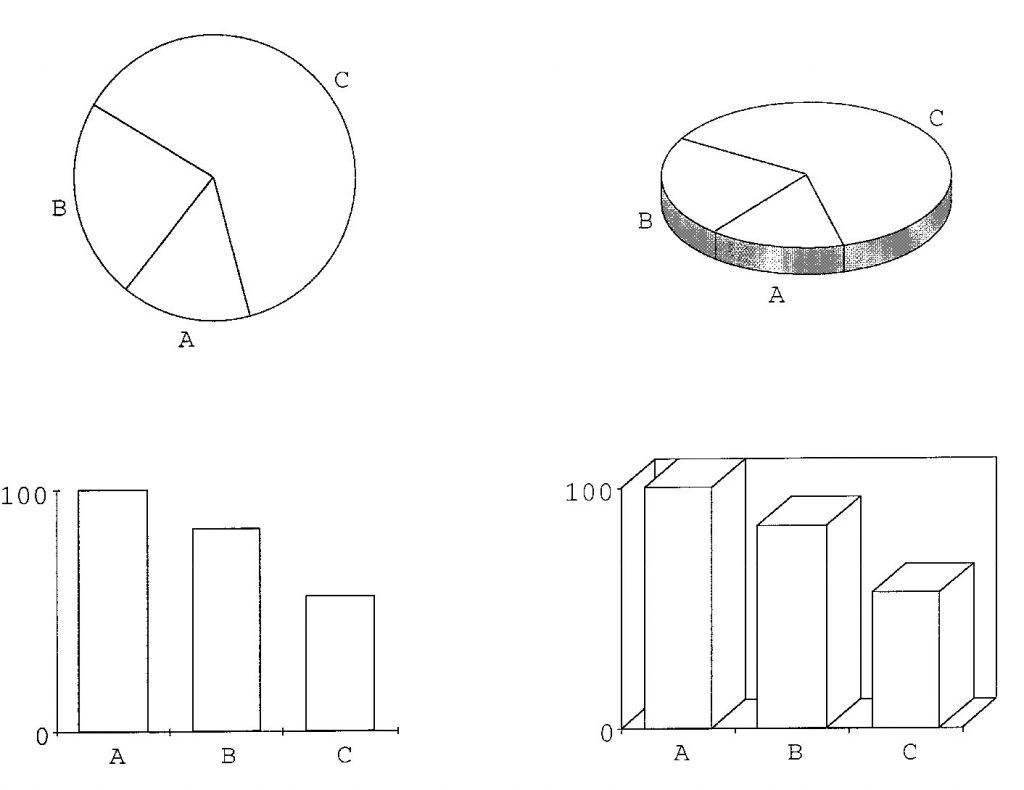
Siegrist спостерігав як точно учасники могли оцінити різницю в розмірах елементів в 2D та 3D варіантах кругових та стовпчикових діаграм. Учасники були однаково точні як в 3D стовпчиковій діаграмі, так і в 2D, проте точність була меншою в 3D кругових діаграмах.
Siegrist (лінк) приходить до висновку, що серед стовпчикових діаграм, 2d не ліпше за 3d, але 3d графіки займають трохи більше часу на сприйняття. Щодо кругових діаграм, 2d ліпші, бо кут в перспективі вносить велику похибку в те, наскільки точно ми оцінюємо сегменти, швидше за все, це виникає, тому що деякі з сегментів більш темні, ніж інші.
Леві та співавтори (лінк) визначили, що 3D-графіка, в той час хоч і «викликаючі» та «сексуальні», не передають ніякої додаткової інформації та змушують читача «розібратися з надлишковими і сторонніми речами.»
В двох окремих експериментах в одному досліджені, Levy та співавтори пропонували учасникам декілька 2D та 3D графіків для вибору.
Учасникам була надана можливість вибрати одну з 2D і 3D діаграм. Коли учасників попросили обрати діаграму, щоб представити іншим людям, вони, як правило, обирали 3D графіки. Також обирали 3D графіки, коли їм говорили, що дані потрібно буде запам’ятати. Учасники обирали 2D діаграми частіше, коли їм говорили, що необхідно передати конкретні деталі, а також обирали лінійні діаграми, коли повідомлення потрібно було передати швидко. Автори прийшли до висновку, що 3D-графіки можуть бути корисні в деяких випадках.
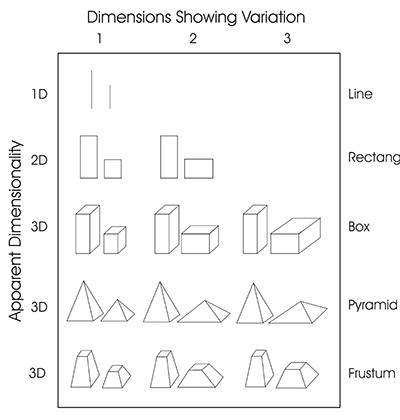
Spence дізнався, що люди сприймають спотворення, що описане в законі Стівена, коли відбувається зміна в два чи більше розмірах однієї фігури. якщо змінюється лише один показник (наприклад, висота) між фігурами, то спотворення відсутне.
Останні два експерименти, проведені Spence (лінк1, лінк2), мають справу з законом Стівена, що знову-таки (дуже спрощено) говорить, що розмір об’єкта сприймається більшим, коли представлені більш великі об’єкти, або меншим, коли представлені більш дрібні об’єкти. Спенс виявив, що всупереч поширеній фізиці, це спотворення не відбувається при порівнянні двох фігур однієї і тієї ж розмірності. Тільки тоді, коли ви міняєте розмірність серед фігур робить це спотворення відчутним.
Більше думок про точкову діаграму
Cleveland та співавтори (лінк) виявили, що люди роблять висновки про кореляції в діаграмах розсіювання частково на основі розміру хмари точок. Коли ж співвідношення представлено в двох графіках, але в одному з них масштаб збільшений, так що хмара точок стає дуже малою (скупченою), люди сприймають наче значення кореляції більше.
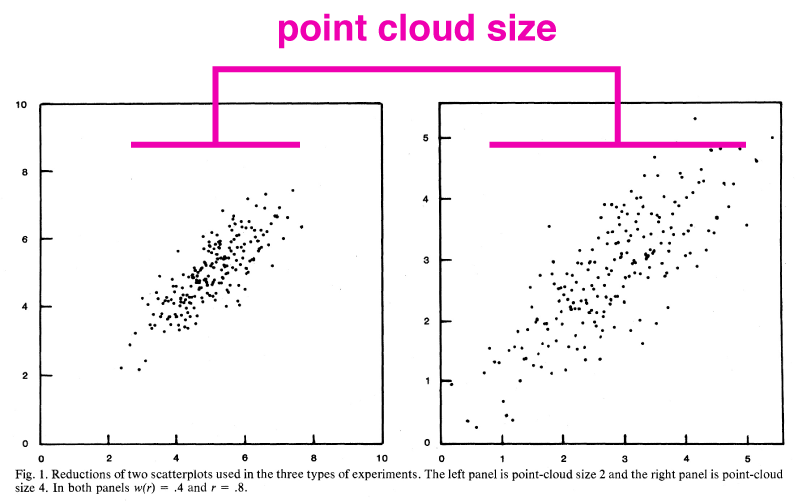
Cleveland та співатори дізналися, що зміна розміру хмари точок сама по собі може вплинути на виникнення неточності в розрахунку кореляції в діаграмі розсіювання.
Експериментуючи з типом символів в діаграмах розсіювання, Lewandowsky та Spence (лінк) знайшли, що зміна кольору є найбільш помітною для ока. Коли немає змоги використовувати кольори, то автори рекомендують використовувати заповнення або фігури (або, навіть, контрастні між собою, літери) — великої втрати точності не відбудеться.

Lewandowsky та Spence дізналися, що може найточніше розрізняти зміну кольорів в знаках, що використовуються в діаграмі розсіювання.
Автор припускає, що використання літер має одну явну перевагу: надання напів-міток для даних (M для чоловіків; F для жінок). Я особисто думаю, що це може бути досягнуто за допомогою анотації без ризику змістити положення центроїда символів.

Demiralp та співавтори змінили позиції існуючої панелі кольорів та символів в Tableau, так що вони були відранговані, як людині легше сприйняти їхню відмінність.
У натовпу джерел експерименті, Demiralp та співавтори (лінк) змінили розміщення оригінальної палітри кольорів та симовлів Tableau так, щоб кольори та символи були б відсортовані за правилом «найбільш помітний для очей».
Treemaps
Ziemkiewicz і Kosara (лінк) виявили, що якщо направляти учасників під час навігації по treemaps з використанням метафор для виконання певних завдань, то це робить їх більш точними. Наприклад, направляючи учасників, щоб знайти точку даних «всередині» контейнера в Treemap; чи говорити їм, щоб шукали «нижче» в каскадні Treemap працювали краще.
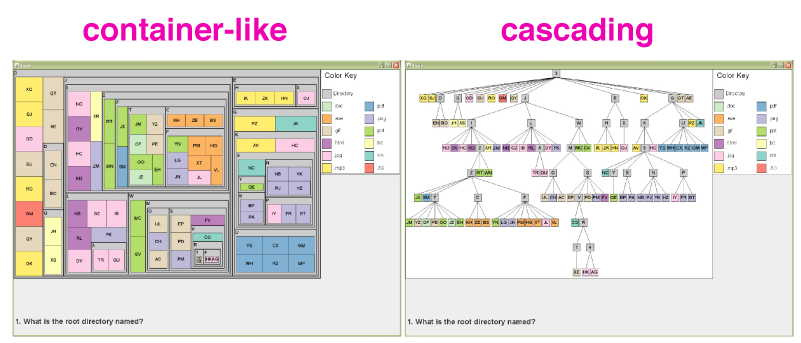
Ziemkiewicz та Kosara використовували візуальні метафори, щоб направляти учасників для виконання простих завдань з різними видами treemaps. Коли візуальні метафори співпадали з відповідним стилем treemap, учасник був більш точним.
Kong, Heer та Argawala (лінк) виявили, що люди ліпше розрізняли значення в Treemap, коли компоненти були прямокутниками з різним співвідношенням сторін. Парадоксально, але квадрати важче порівнювати один з одним. Екстремальні співвідношення в прямокутниках також неефективні для порівняння.
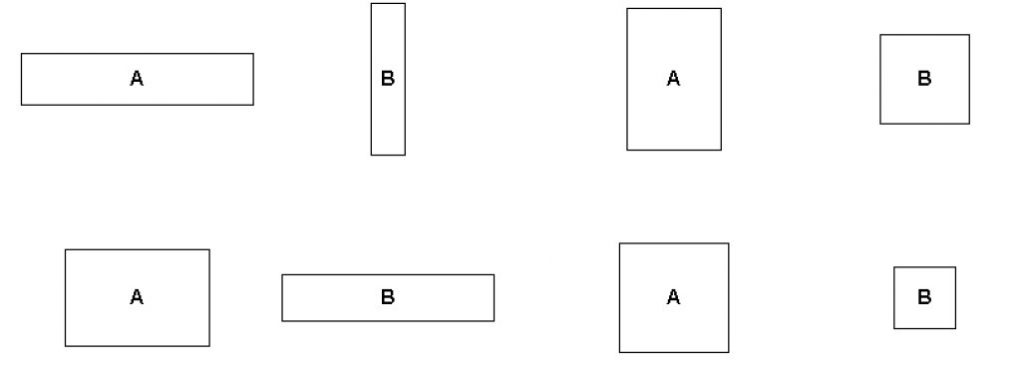
Есперемент Kong, Heer and Argawala показав, що люди не настількі точні в порівнянні розмірів квадратів, ніж при порівнянні прямокутників з різними пропорціями.
Крім того, вони виявили, що, як не дивно для них, невеликі стовпчикові діаграми були краще, ніж Treemaps, для представлення наборів даних, в яких менш ніж 1000 точок для порівняння між «листями».
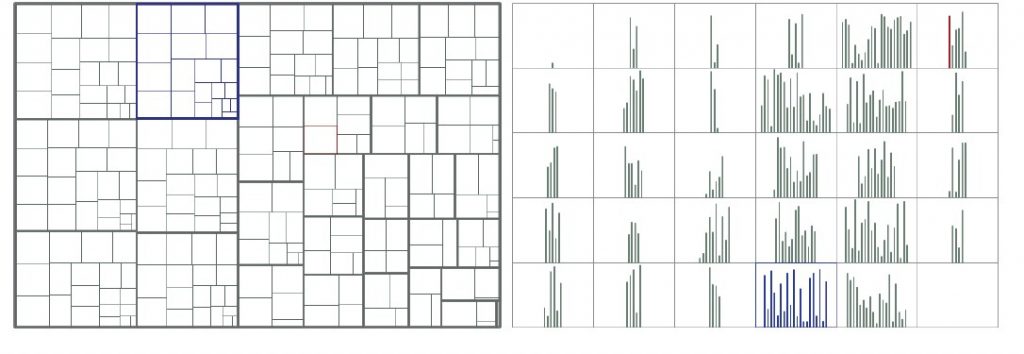
Учасники були більш точними при поелементних порівняннях в наборі малих діаграм, ніж в treemap.
Інші види візуалізацій
В 2011 році, Barlow та Neville (лінк) просили учасників порівняти 4 різні ієрархічні діаграми. Вони дізналися, що учасникам не подобалися treemaps, і вони віддавали перевагу організаційним діаграмам (org charts) та icicle charts.
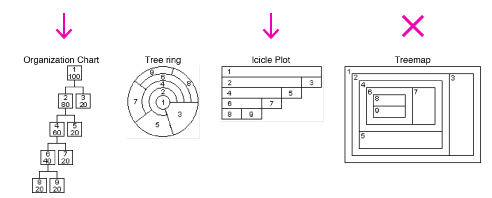
В досліджені Barlow та Neville, учасники не зважали на treemap.
В 2007, Cawthon та Moere (лінк) показали, що естетика може бути пов’язана з персональною зацікавленністю до відповідної візуалізації. Автори виявили, що sunburst була найбільш популярна, та учасники обрали 3D beam tree найбільш заплутаною. Найбільшу зацікавленість викликали sunburst, icicle and startree. Найменшою ефективністю відзначалися beamtree and treemap. Автори констатували, що sunburst є прикладом «ефективної краси» («beautiful can be useful»).
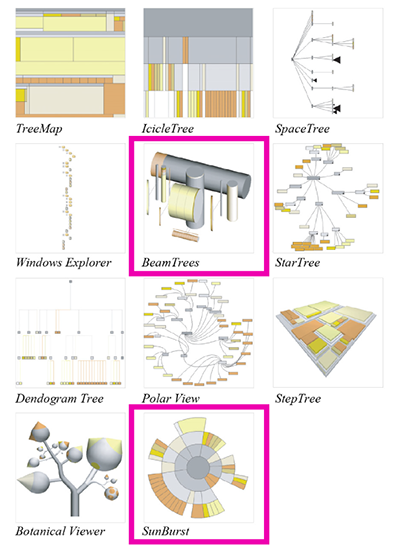
В дослідженні Cawthon and Moere, учасники віддали перевагу sunburst.
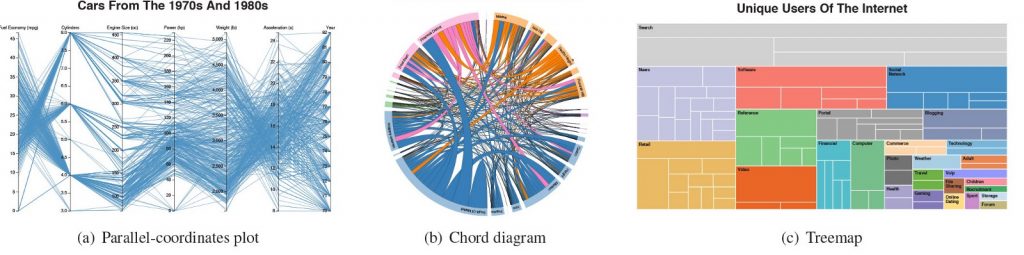
Harrison та колеги (лінк) відсортували за ефективністю розпізнавання кореляції декілька типів візуалізацій. Вони виявили, що діаграма розсіювання та «паралельні осі» найкраще підходять для цієї задачі. Серед блочних діаграм, стовпчикова діаграма значно випереджає інші: stacked area та stacked line.
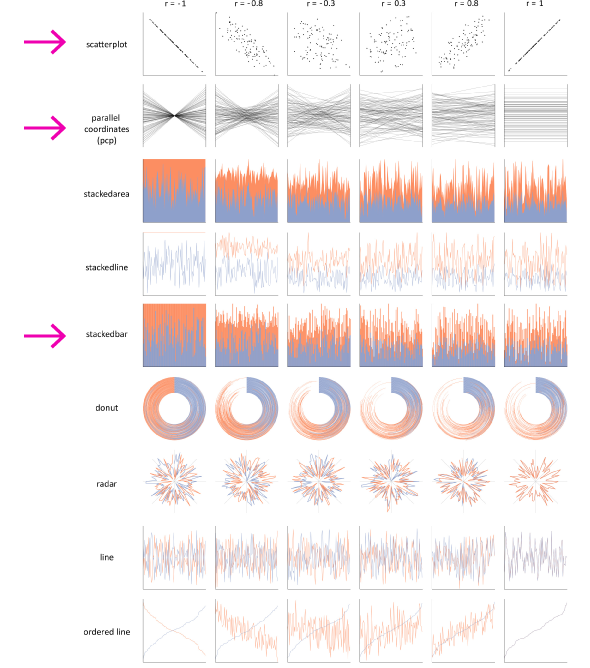
Harrison та колеги визначили, що учасники можуть найпростіше визначати кореляцію в діаграмах розсіювання (як для негативної, так і позитивної кореляції) та діаграмі «parallel coordinate» ( тільки для негативної кореляції).
Kay та Heer повторили дослідження Harrison’a (лінк) та розділили візуалізації на 4 групи за рівнем точності. TOP візуалізацій, як не дивно, залишився без змін.
Густина даних (data density)
Heer, Kong і Argrawala (лінк) досліджували, наскільки може бути щільний графік, щоб все ж бути ефективним при передачі значень. Вони відображали негативні значення в графіках часових рядів та замальовували крайні значення в 2, 3 і 4 кольорові смуги, ефективно зменшуючи розмір діаграми на 75 відсотків. Вони також маніпулювали висотою діаграм таким чином, що деякі виявилися тільки 6 пікселів в висоту.
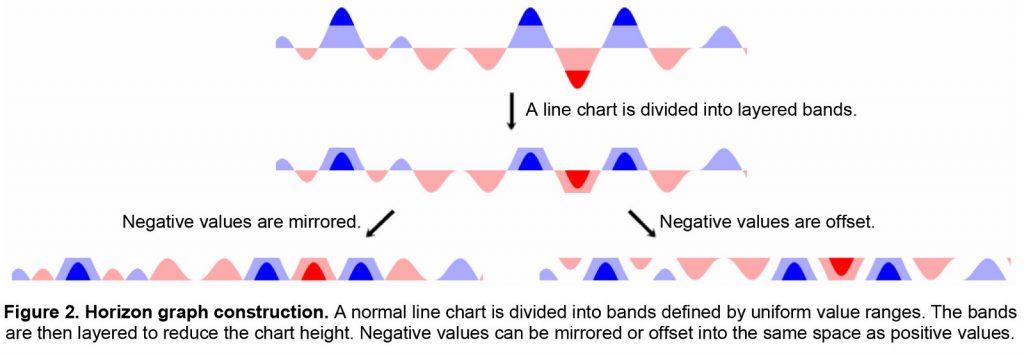
Експерименти Heer, Hong and Argrawala включали графіки часових ряді, які були зменшені до 25% вихідного розміру.
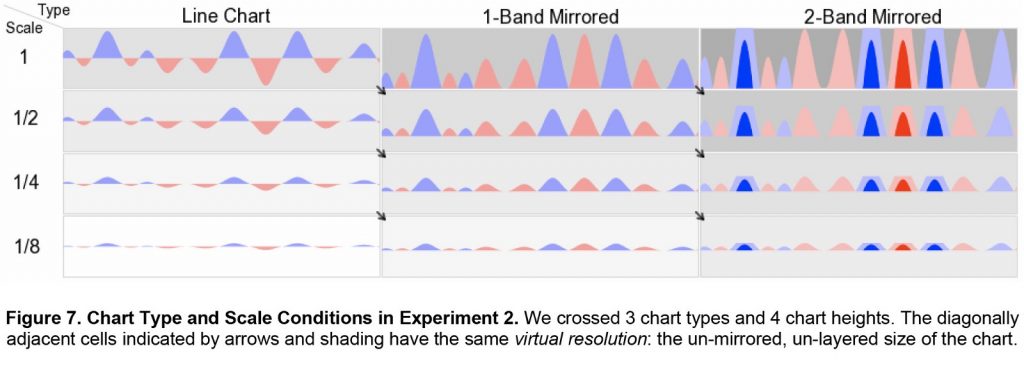
Дослідники зменшили висоту графіка, щоб перевірити, наскільки ефективно може бути сприйнято віддзеркалювання та виділення.
Вони виявили, що чим більше кольорових смуг присутні в графіках, тим більше людей робили помилки. Автори дослідження припускають, що іноді не всі візуальні маркери можуть бути корисними для читачів. Звичайні лінійні графіки показували найгірший результати при малих розмірах, показуючи, що ефект відзеркалення не впливає на розуміння.
Використання піктограм та малюнків
Haroz, Kosara і Franconeri (лінк) експериментували з використанням піктограми замість класичних фігур для відображення даних в простих графіках. Вони виявили, що використання дискретних форм, чи то класичні кола, чи піктограми, допомогали людям краще запам’ятовути дані, ніж один стовпчик(прямокутник). Використання піктограм у якості заміни для тексту на осі призводило до більших помилок.
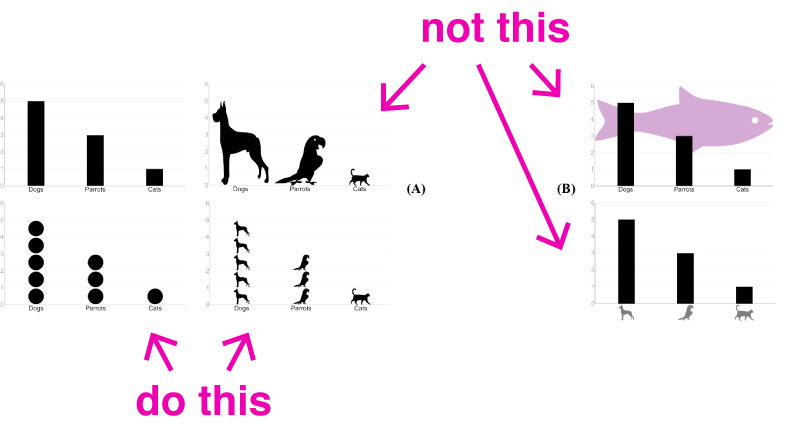
Haroz, Kosara and Franconeri дізналися, що заміна відповідних елеменів на відповідні піктограми не призводила до зниження точності серед учасників.
Вони виявили, що заміна класичних фігур на піктограми не призводить до впливу на сприйняття або запам’ятовування даних, представлених в складених стовпчикових діаграмах (stacked graphs). Люди були більш схильні досліджувати зорові образи, які використовували піктограми, на відміну від тих, що використовували класичні фігури.
В одному з моїх улюблених досліджень, Cole та співавтори (лінк) досліджували, чи учасники могли розрізнити векторні об’єкти створенні комп’ютером та художником. Вони виявили, що багато алгоритмів, доступних на сьогоднішній день, дійсно можна порівняти з людськими візуалізаціями, але деякі все ж не проходять тест.
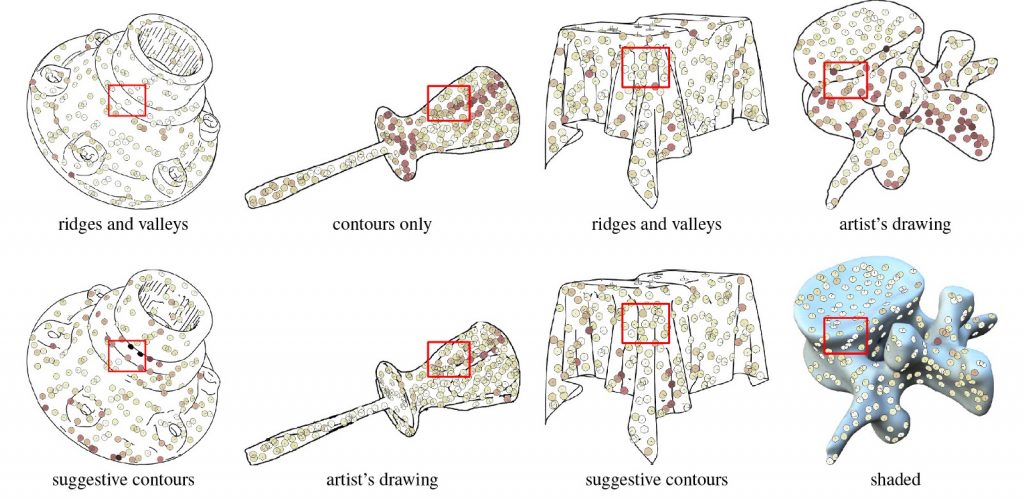
Cole та співавтори просили учасників Mechanical Turk розпізнати які фігури були намальовані комп’ютером чи людиною.
Моделі, які були найскладніші для учасників опитування, мали, як правило, «гладкі, аморфні форми.» Навіть коли учасники інтерпретували об’єкти неточно, все ж їхні інтерпретації були схожі один на одного, і вони зосереджувалися в виділених, «гарячих» точках на об’єктах.
Вплив аудиторії
Ziemkiewicz і співавтори (лінк) оцінювали, як особистісні риси впливають на ефектиність сприйняття візуалізації у вигляді списку та візуалізації у контейнерному вигляді.
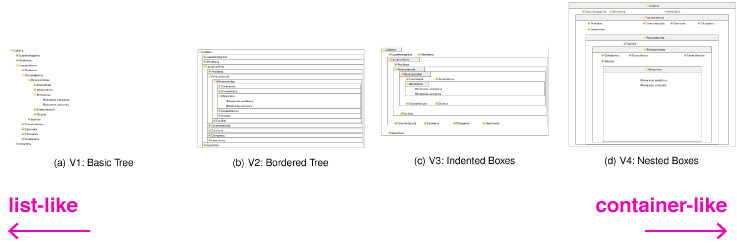
Ziemkiewicz та співавтори тестували учасників завданнями, що включали ієрархічні графіки, що мали вигляд списку чи контейнерів.
Учасники з високим внутрішнім LOC (ті, хто вважає, що може контролювати зовнішні фактори) були не такі вправні в розумінні контейнер-подібних візуалізацій. Ті ж, хто мав високий зовнішній LOC (вважають, що вони легко піддаються зовнішнім факторам) вправляються швидше та точніше в цілому.
Крім того, більш невротичні учасники були найкращі в роботі з більш структурованими (контейнерними) візуалізаціями, в той час як інші учасники проявили протилежну тенденцію. Інтроверти були більш точні в цілому, ніж екстраверти.
Lee та співавтори (лінк) спостерігали за «новими користувачами», коли вони стикалися з незнайомими візуалізаціями, і намагалися розібратися в них. Учасники мали труднощі при виході за межі своїх початкових уявлень, навіть якщо вони були неправильними. Таким чином, перші враження дуже важливі.
Lee та співавтори пропонували учасникам візуалізації, з якими вони не були знайомі, та тестували їх продуктивність з відповідним типом графіка.
Harrison і співавтори (лінк) надавали учасникам статті New York Times, намагаючись зачіпити їхні емоції або позитивно, або негативно, і перевірити, наскільки добре вони себе покажуть в простих завданнях сприйняття.
Вони виявили, що негативно налаштовані учасники робили більше помилок, а позитивно налаштовані показували тенденцію до поліпшення ефективності. Тільки у 1/5 випадків успішно налаштованому учаснику було важко виконати завдання.
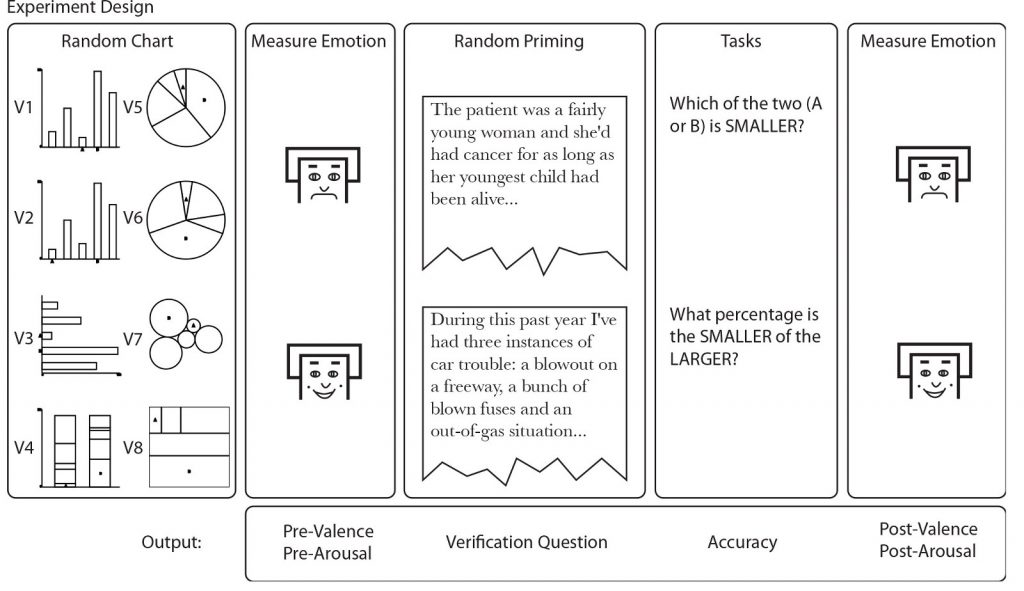
Harrison та співавтори пропонували учасникам статтю, спрямовану вплинути на їхні емоції, та оцінювали їхню ефективність при виконанні стандартних завдань з графіками.
Hullman, Adar та Shah (лінк) перекликаються з ранішим дослідженням Heer та Bostock з Mechanical Turk, але з одною істотною відмінністю. Вони показали соціальну гістограму останніх 50 реакцій, відповідей учасників на питання. Для деяких учасників, гістограму було зрушено вгору або вниз від реальних значень. Це вказує на те, що неправильні гістограми викликали більше неправильних питань.
Наявність інтерактивних елементів
Liu та Heer (лінк) виявили, що затримка в півсекунди в інтерактивній графіці має глибокий вплив на те, як глядач зацікавлюється графікою. Учасники рухали менше мишкою, змінювали типи взаємодій, та зменшили деякі з їх взаємодій в цілому. Також вони були більш схильні до усного коментування інтерфейсу.
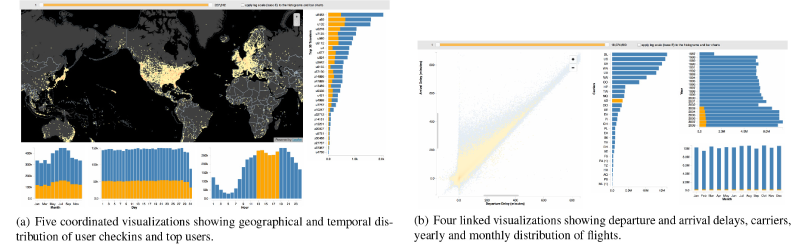
Liu and Heer вказували учасникам як працювати з двома різними візуалізаціями з 1 мільйоном рядків даних кожен, та спостерігали як затримка в півсекунди впливає на взаємодію.
Ця затримка також впливала на наступні сеанси для даного конкретного учасника; він або вона була менше зацікавлена в графіці під час наступного сеансу. Спочатку дослідники хотіли також додати затримку в 1 секунду, але в ході пілотних дослідженнь, вони знайшли це недоцільним.
У 2007 році Wigdor та співавтори (лінк) виявили, що було набагато складніше виконати елементарні завдання сприйняття, такі як виявлення положення або куту напрямку, якщо екран лежав на столі. Таким чином, орієнтація екрану може спотворювати сприйняття візуалізації.
У 2008 році Robertson та співавтори (лінк) дали учасникам великий набір даних представлений трьома різними способами: анімація, узагальнена статика, та набір невеликих статичних візуалізацій — і задавали їм питання з приводу даних.
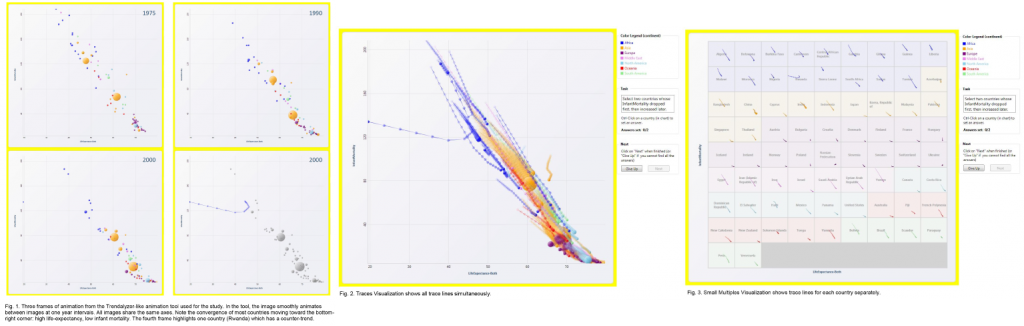
Robertson та співавтори розраховували ефективність серед трьох видів візуалізацій, що відображали однаковий набір даних: анімована графіка, узагальнена статика та набір маленьких графіків.
Навіть якщо версія анімації вигравала раз за разом в опитуванні корисності, простоти використання, задоволення, хвилювання; дослідники вказали, що версія набору статичних візуалізацій була більш ефективна для великих наборів даних, була швидша для сприйняття та призводила до меншої кількості помилок.
Колір
Нарешті, в ще одному з моїх улюблених досліджень, Lin та співавтори (лінк) створили алгоритм для ідентифікації «семантично резонуючого кольору». Наприклад, якщо я хочу поговорити про океан, я використовую синій колір. Якщо я хочу поговорити про любов, я використовую рожевий або червоний колір.
Алгоритм аналізував Google Images та присвоював певний колір до ключового слова. Вони перевірили, наскільки добре цей алгоритм працює на учасниках Mechanical Turk. Деякі з них виявилося трохи кумедними.
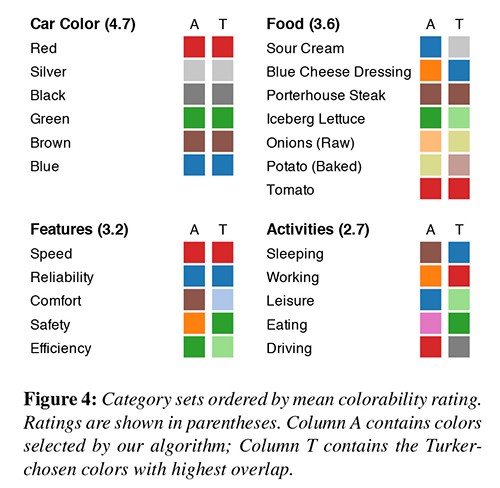
В першому досліджені, Lin та співавтори перевіряли як добре їх алгоритм приписує кольори до відповідних ключових слів, та порівнювали результати з результатами, зробленими учасниками Mechanical Turk.
У більш пізньому експерименті в тому ж дослідженні, художник з Tableau створив семантично резонансну схему кольорів, і дослідники перевірили свій алгоритм з цією схемою та з не-семантичною схемою кольорів. Вони робили ставку проти свого власного алгоритму, припускаючи, що підібрана людиною палітра буде найбільш ефективною.

В другому досліджені, автори оцінювали наскільки учасники точні під час простих завдань порівняння серед трьох кольорох палітр. Вище наведені кольорові співвідношення зроблені алгоритмом та учасниками.
Але виявилося, що алгоритм створив палітру схожу на створену людиною з невеликими розбіжностями.
Підсумок
Які висновки ми можемо зробити з цих досліджень? Що ще залишилося розкрити?
Як ці результати зміняться, коли візуалізація стає все більш поширеним явищем, і люди стають візуально більш обізнаними?
Що ще більш важливо, що ви думаєте про питання Colin Ware про те, що візуалізації даних — це наука чи мова?
Я не думаю, що візуалізація даних або data storytelling являється чимось фіксованим; Я думаю, що є багато варіантів, і нескінченне число можливих візуалізацій, багато ми ще навіть не відкрили.
Але, можливо, це не чисто мова в той же час. Очевидно, що існують упередження і ми приносимо спотворення з нами при перегляді графічних шаблонів та об’єкти, деякі з яких є набутими, але деякі з яких здаються вродженими.
Я не натякаю, що результати цих досліджень повинні бути повністю та без заперечень застосовані до графіків. Більшість цих досліджень перевіряють точність дуже специфічних завдань, в основному, що стосуються здатності людини сприймати відмінності в розмірах визначених форм та елементів. Це часто неголовна мета візуалізації.
Висновки про Treemaps ілюструють цю помітку: учасники були більш точні з набором малих стовпчикових діаграм, ніж з Treemaps для порівняння між «листям». Це корисно враховувати, проте, цілком можливо, що представлення всієї екосистеми даних є більш важливим.
Ще так багато чого залишилося вивчати в сфері людського сприйняття графіків, особливо з динамічної та інтерактивної графіки. Ми всі виграємо, коли практики діляться своїм дослідницькими знаннями, що може дати нам уявлення про великі пробіли в знаннях, що в даний час не охопленні дослідженнями.
Післямова особисто від мене :)
Сподіваюся, підбірка хоча б підкаже як не варто робити і як ліпше підбирати візуальні елементи до ваших даних та бачення тверджень.
Ще лінки на цю тему:
- Розділ «Data Visualization for Human Perception» з книжки «The Encyclopedia of Human-Computer Interaction, 2nd Ed.» від Stephen Few: https://www.interaction-design.org/literature/book/the-encyclopedia-of-human-computer-interaction-2nd-ed/data-visualization-for-human-perception
Відео з конференції:
мініатюра до статті: techtarget.com