Цей пост — невеликий огляд трьох сторонніх інструментів з маніпуляції та перевірки даних (не R, хоча опис може здатися схожим). Вирішив написати про це, бо достовірність та якість даних дуже важлива, адже на пряму впливає на результат роботи: висновки, намальовані графіки та діаграми, написані статті тощо.
Джерела даних, на мою думку, не в усіх випадках дають однозначно коректно відформатовані дані (завжди згадую про поняття TIDY DATA) і тому потребують перевірки та відповідних змін, при необхідності. Від людських помилок ми ніколи незастраховані. На своїй практиці, за звичай, з подібними ситуаціями зіштовхувався, коли намагався відкрити/завантажити дані в R або Tableau, і вже в середині намагаєшся їх дослідити та змінити. Але з’явилися декілька сторонніх іструментів, що направлені на допомогу з перевіркою даних та підкоректувати їх, за потреби, до початку аналізу. В них дані можна перевірити на основні помилки: дубляж даних, порожні рядки, outliars тощо.
Data Proofer
Почну з більш простого та свіжішого — DataProofer, представлений Knight Foundation.
За описом авторів: «Data proofer is built to automate this process of checking a dataset for errors or potential mistakes.»
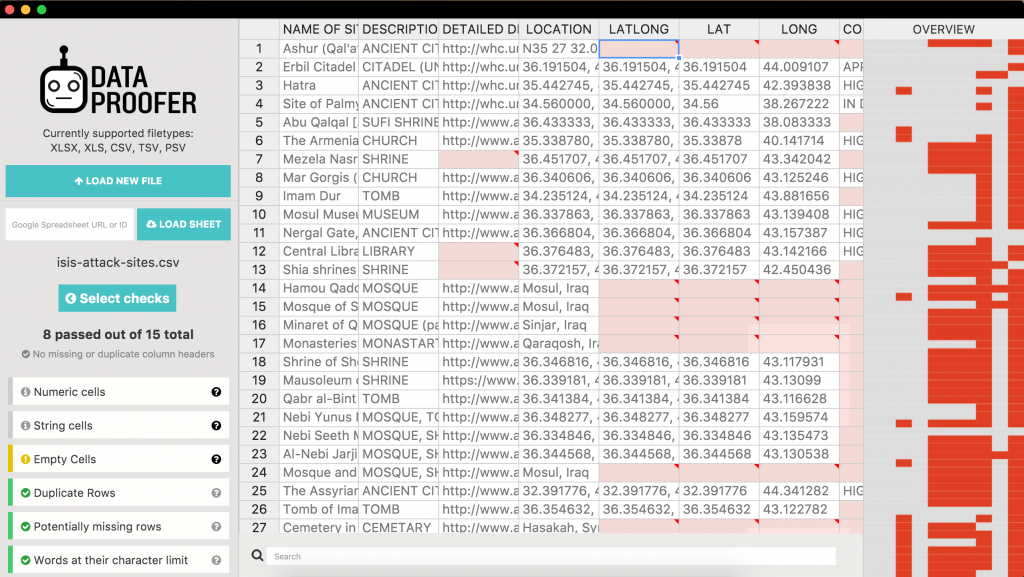
В середині вас очікує підримка основних форматів даних: XLSX, XLS, CSV, TSV, PSV + підримка Google Spreadsheet. Обмеження по розміру файла — 100 Мб, та й для великих файлів автори рекомендують розбивати на частини по 10 тис рядків. В арсеналі програми наявні 15 тестів на перевірку ваших даних. Основні та й найбільш поширені, на мій погляд, перевірки:
- використання одного тип даних (рядок чи число) в колонці
- наявність порожніх клітинок
- присутність повторів
- потенційна відсутність рядків ( це здебільшого стосується старого формату Excel 2003-, .xls, з обмеженням в 65 тис. рядків)
- наявність outliers по медіані та середньому
Для картографів, та й для географічних даних присутні два тести:
- перевірки широти та довготи
- наявність абстрактної точки відліку (0,0)
В додаток до всього розробники залишили можливість створювати власні тести, але для цього потрібно буди знайомим з GitHub (див.сюди)та JavaScript.
Враження: простий та достатньо зручний інструмент для перевірки даних. Тільки залишається проблема — створити звичку перевіряти дані ним :)
Trifacta Wrangler
Наступний «гвоздь» програми — Trifacta Wrangler, представлений одноіменною компанією Trifacta, що займається розробкою продуктів по роботі з Big Data. Сама програма призначена для підготовки даних до аналізу, а саме визначення можливих проблемних елементів та створення нових даних на базі існуючих (щось схоже на dplur::mutate з R).
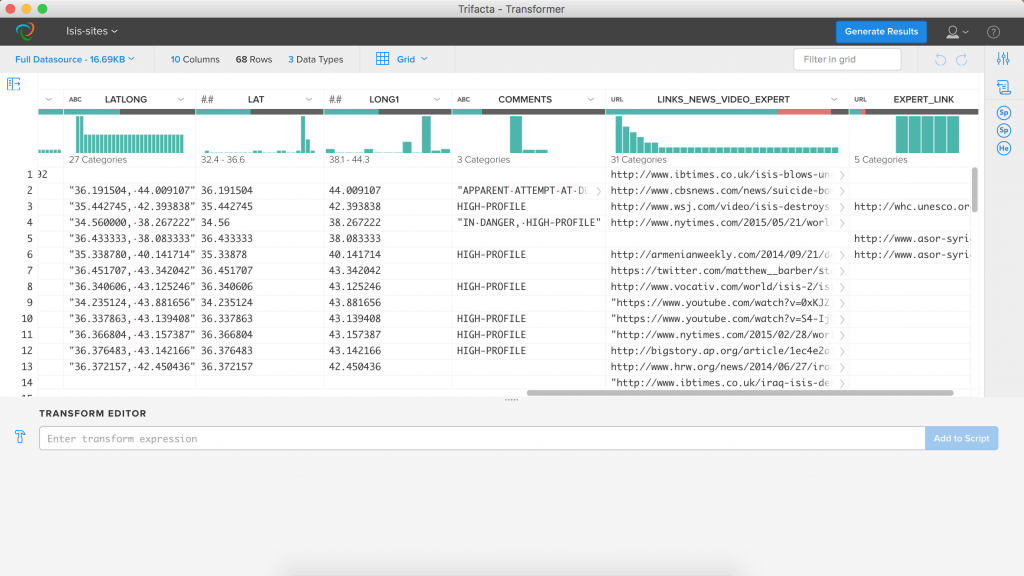
Для користування для початку потрібно буде зареєструватися. В середині ви знайдете підтримку основних форматів даних: csv, xlsx та json, але за описом авторів можна запихнути й інші текстові документи (мені цього так і не вдалося). Ще одним помітним недоліком, на мій погляд, є неінтуітивний інтерфейс — дуже багато просто клацав, намагаючись знайти як додати новий датасет.
Щодо того як він працює в середині, то тут достатньо проста логіка:
- підключаєш датасет
- модифікуєш/досліджуєш його
- зберігаєш в необхідному тобі форматі
**Так ви правильно прочитали — ви можете конвертувати свої дані з формату в формат, наприклад з csv в json, та навпаки.
При бажані модифікувати дані програма запропонує набір можливих дій та покаже прев’ю результатів, але залишає можливість запрограмувати необхідні дії достатньо простою, на мій погляд, внутрішньою мовою. Хоча мені як людині, що постійно працює з кодом, всі сучасні мови програмування знаються знайомими за синтаксисом, або хоча б мають щось спільне ( наприклад, цикли :) )
Враження: на перший погляд, достатньо потужна машина, з певним майбутнім, особливо за рахунок гручкого маніпулювання даними — можливість програмувати свої скрипти зміни даних. Але до неї потрібно звикати: складно зрозуміти, що до чого та яка послідовність дій.
Exploratory
Третій інструмент цього огляду відмінний від попередніх двох, по-перше, що він має більш ширший функціонал, по-друге, в своїй основі базується на R (при встановлені інсталюються R разом з пакетами та Git).
Exploratory — творіння рук Kan Nishida, якщо я зміг правильно знайти взаємозв’язки. За описом автора це «UI for R» та «provides an interactive and reproducible real data wrangling and analysis experience powered by R and visualization». Вже існують версії для Mac та Windows, але щоб потестити програму потрібно спочатку зареєструватися на тестування, надіславши e-mail (особисто, чекав 2 дні).
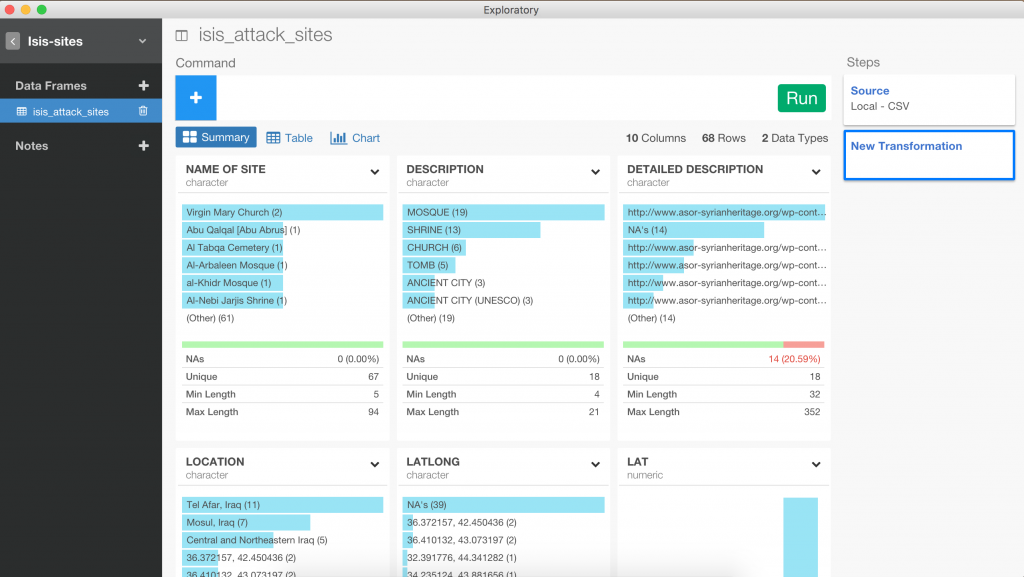
В середині все просто: інтерфейс нагадує Trifacta Wrangler (проте зрозуміліший), але відчувається присутність R :) Хочу відмітити зручне та функціональне меню завантаження даних з величезною кількістю фільтрів (сепаратори, тип кодування тексту тощо), які одразу можна застосувати, щоб завантажені дані відповідали вашим очікуванням.
А далі починається, мабуть, рай для тих хто знайомий з R — вам доступні більшість звичних функцій з бібліотеки dplyr і не тільки + ви можете одразу створювати графіки. Чудо, а не софт. Сподіватимемося, що Exploratory знайде свою нішу.
Враження: певна альтернатива до Rstudio, хоча з меньшими можливостями та й задачі інші, але приємна у користуванні.
—
На цьому все — сподіваюся було корисно.
рекомендації та відгуки пишіть в FB.com/taras.rodynenko